
All in all pretty decent sorry I attached a 35 min video but didn’t wanna link to twitter and wanted to comment on this…pretty cool tho not a huge fan of mark but I prefer this over what the rest are doing…

The open source AI model that you can fine-tune, distill and deploy anywhere. It is available in 8B, 70B and 405B versions.
Benchmarks
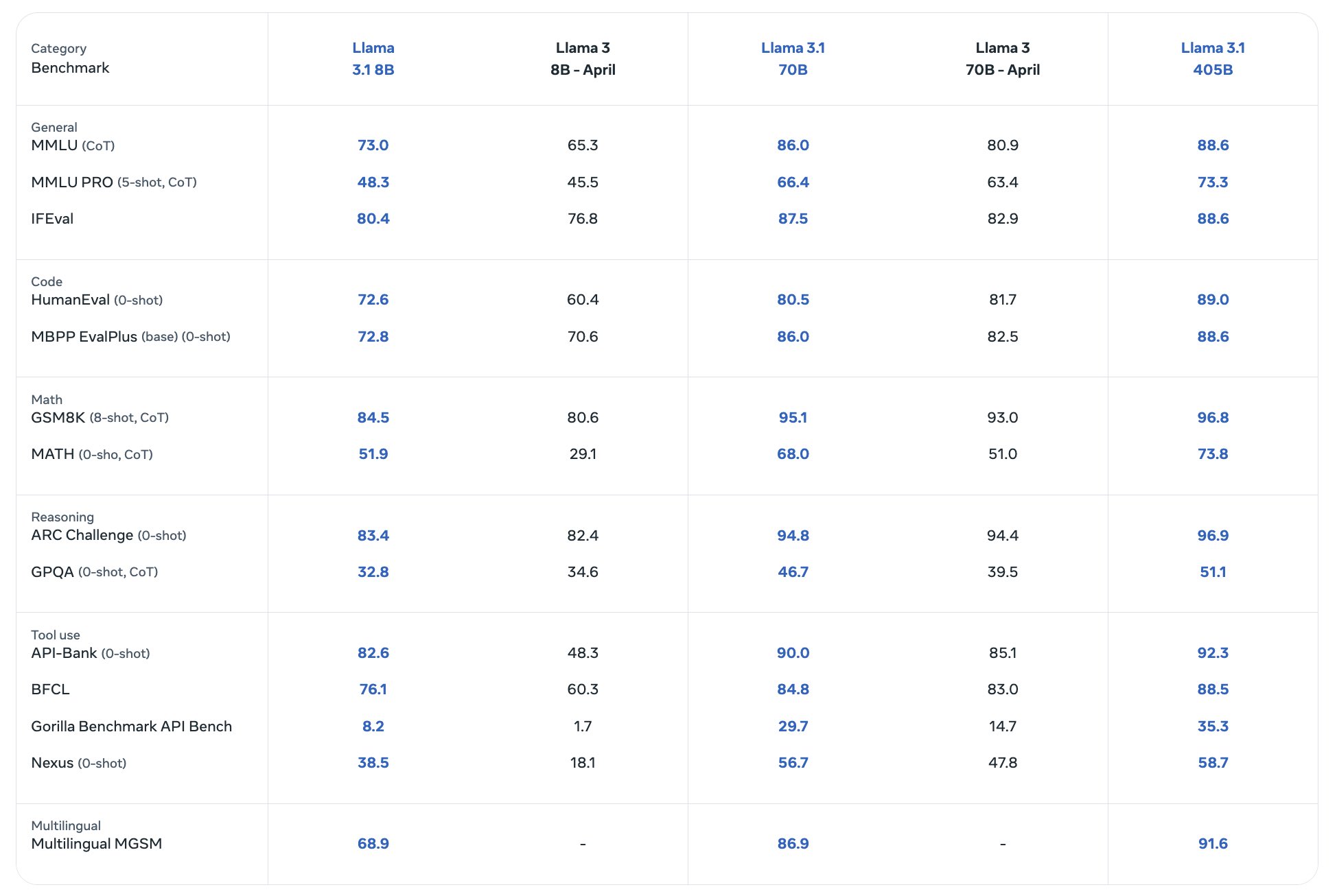
What is the parameter count for the famous proprietary models like gpt 4o and claude 3.5 sonnet?
They don’t tell. There is lots of speculation out there. In the end I’m not sure if it’s a good metric anyways. Progress is fast. A big model from last year is likely to be outperformed by a smaller model from this year. They have different architecture, too. So that count alone doesn’t tell you which one is smarter. A proper benchmark would be to compare the quality of the generated output, if you’re interested to learn which one’s the smartest. But that’s not easy.
I am not really concerned with which one is better or smarter but with which one is more resource intensive. There is a lot of opacity about the cost in a holistic sense. For example, a recent mini model from OpenAI is the cheapest smart (whatever that may mean) model available right now. I wanna know if the low cost is a product of selling on a loss or low profit margin, or of an abundance of VC money and things like that.
Well, I don’t know if OpenAI does transparency and financial reports. They’re not traded at the stock exchange so they’re probably not forced to tell anyone if they offer something at profit or at a loss. And ChatGPT 4o mini could be way bigger than a Llama 8B. So automatically also more resource intensive… Well… it depends on how efficient the inference is. I suppose there’s also some economy of scale.